Analisis_Predictivo--Regresion_Ridge
Predecir la Satisfacción con el Trabajo
Predecir la satisfacción laboral mediante Regresión Ridge

1. Establecer el directorio de trabajo y cargar los datos
import os
import pandas as pd
os.chdir('C:/Users/Alejandro/Documents/')
df = pd.read_csv('jobsat3881.csv')
df.info()
2. Importar bibliotecas
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
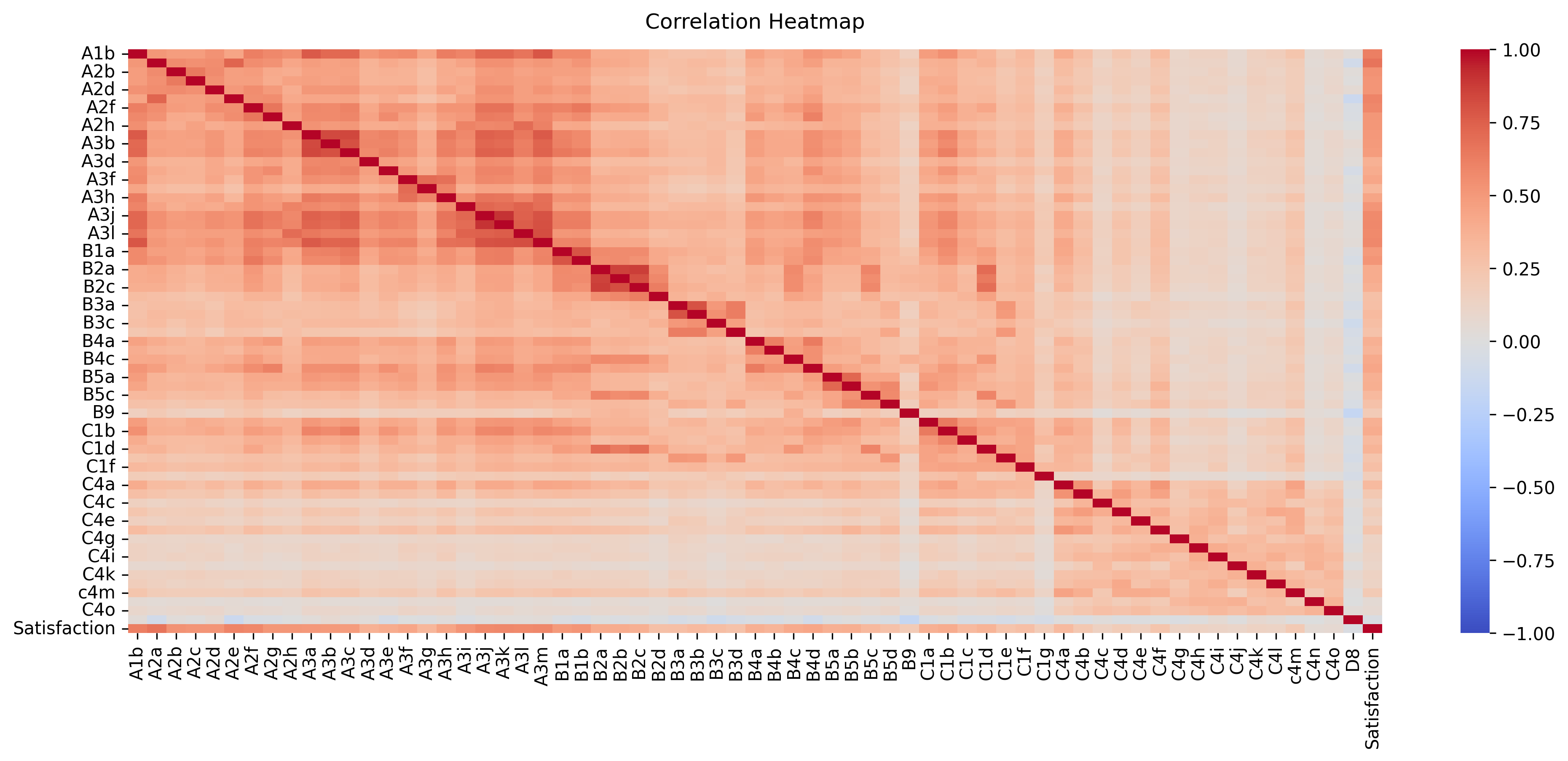
3. Mostrar la matriz de correlación
Almacene el objeto HeatMap en una variable para acceder fácilmente cuando desee incluir más funciones (por ejemplo el título). Establezca el rango de valores que se mostrarán en el gráfico de -1 a 1, y establezca la anotación en verdadero para mostrar los valores de correlación en el mapa de calor.
plt.figure(figsize=(16, 6))
heatmap = sns.heatmap(df.corr(), vmin=-1, vmax=1, annot=False, cmap='coolwarm')
heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':12}, pad=12)
plt.savefig('Correlation_matrix.png', dpi=300, bbox_inches='tight')
4. Extraer la variable a predecir (target) y los predictores (features) desde la base de datos
X = df.drop('Satisfaction',axis=1)
y = df['Satisfaction']
5. Dividir la base de datos en los subconjuntos de entrenamiento y testeo
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
shuffle=False,
random_state = 1234)
6. Escalar los datos usando StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
7. Aplicar el modelo de Regresión Ridge
from sklearn.linear_model import Ridge
8. Inicializar el modelo de regresión Ridge con configuración predeterminada
model = Ridge()
9. Aplicar el modelo a los datos de entrenamiento
model.fit(X_train, y_train)
10. Elegir el parámetro de regularización lambda (λ)
from sklearn.linear_model import RidgeCV
11. Configurar una gama de posibles valores de lambda
alphas = [0.1, 1.0, 10.0, 100.0]
12. Inicializar el modelo RidGeCV para encontrar el mejor valor para lambda
ridge_cv_model = RidgeCV(alphas=alphas, store_cv_results=True)
13. Aplicar el modelo a los datos de entrenamiento
ridge_cv_model.fit(X_train, y_train)
14. Mostrar el mejor valor para alfa (lambda)
print(f"Optimal lambda: {ridge_cv_model.alpha_}")
15. Hacer predicciones para el conjunto de datos de testeo
y_pred = model.predict(X_test)
16. Calcular las métricas de evaluación
from sklearn.metrics import root_mean_squared_error
from sklearn.metrics import mean_absolute_percentage_error, mean_squared_error, r2_score, explained_variance_score, mean_absolute_error
mape = mean_absolute_percentage_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = root_mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
explained_var = explained_variance_score(y_test, y_pred)
17. Mostrar las métricas de evaluación
print("MAPE, mean absolute percentage error:", mape)
print("MSE, Mean squared error:", mse)
print("RMSE, Root mean squared error:", rmse)
print("MAE, Mean absolute error:", mae)
print("R2, R-squared:", r2)
print("Explained variance:", explained_var)
RESULTADOS
MAPE, mean absolute percentage error: 0.3386349991569121
MSE, Mean squared error 0.9269658387736589
RMSE, Root mean squared error: 0.9627906515819827
MAE, Mean absolute error 0.687484673325361
R2, R-squared: 0.6014297918574099
Explained variance: 0.6044428373606303
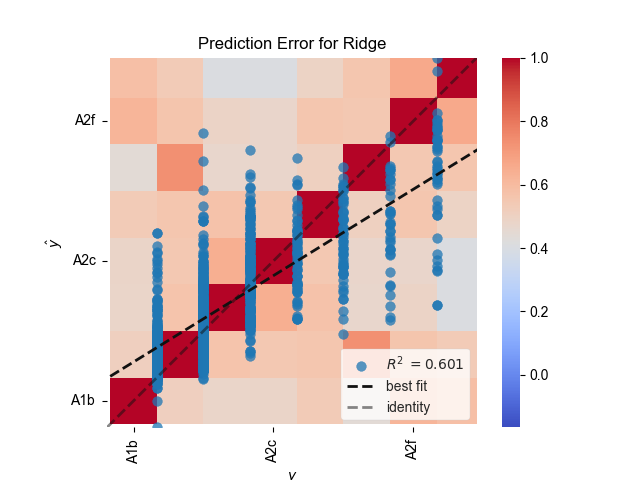
Gráfico del error de predicción
import matplotlib as plt
import yellowbrick
from yellowbrick.regressor import PredictionError
visualizer = PredictionError(model)
visualizer.fit(X_train, y_train) # Ajustar los datos de entrenamiento al visualizador
visualizer.score(X_test, y_test) # Evaluar el modelo en los datos de testeo
visualizer.show() # Finalizar y renderizar la figura
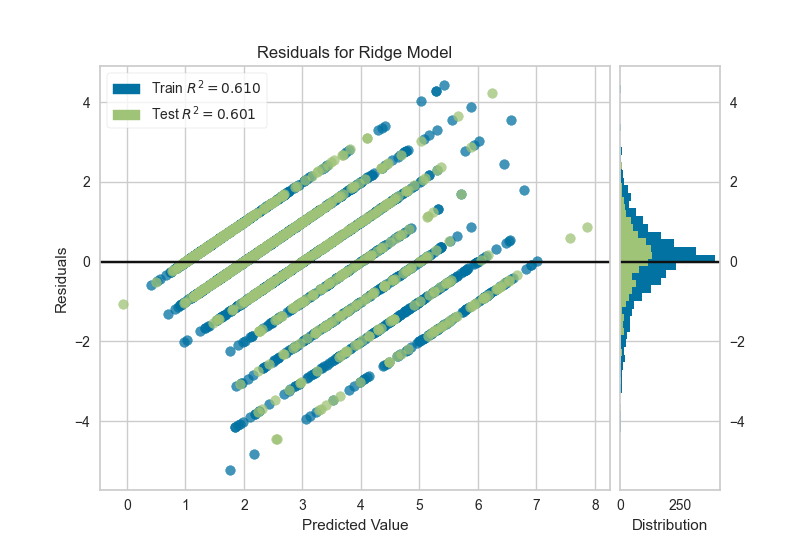
Gráficos de residuos para los datos de entrenamiento y de testeo
from yellowbrick.regressor import ResidualsPlot
visualizer = ResidualsPlot(model)
visualizer.fit(X_train, y_train) # Ajustar los datos de entrenamiento al visualizador
visualizer.score(X_test, y_test) # Evaluar el modelo en los datos de testeo
visualizer.show() # Finalizar y renderizar la figura